Ever crafted the "perfect" message for your favorite Character AI companion, only to have it vanish behind a stark Character AI Censor Words warning? You're far from alone. Millions of users encounter this invisible barrier daily, transforming potentially deep conversations into exercises in frustrating guesswork. This comprehensive guide dives deep beneath the surface of Character AI's filtering system. We'll uncover why seemingly innocent phrases get blocked, reveal the contentious categories under intense scrutiny, analyze the safety vs. creativity tightrope the platform walks, explore proven (and safe) user strategies for more engaging chats, and examine the simmering controversies around communication restrictions in AI platforms. Forget vague speculation – this is an evidence-based exploration of the unseen boundaries shaping your AI interactions.
Beyond the Block: How Character AI Censor Words Actually Work

Character AI employs a sophisticated, multi-layered filtering system designed to uphold community safety standards. Understanding its mechanics is key to navigating it:
The Multi-Layered Defense System
Keyword Flagging: The foundation. A constantly updated lexicon of prohibited and contextually risky terms triggers immediate review or blocking. This includes explicit profanity, graphic violence, hate speech identifiers, illegal acts, and severe harassment phrases.
Contextual Analysis & Intent Detection: Beyond simple keywords. Advanced models analyze surrounding text to understand intent. For example, the word "shot" might be harmless in a medical context ("I need a flu shot") but flagged in a violent or self-harm context. This layer is crucial yet imperfect, often the source of "false positives."
Image Pattern Recognition: Integrated systems scan generated or uploaded images for prohibited visual content, linking this detection back to potential textual violations.
User Feedback Loops: User reports on inappropriate AI responses or blocked user messages feed back into refining the filter algorithms and banned word lists.
This creates a dynamic, evolving filter designed to react to new trends in harmful content. Unlike human moderation, the system acts instantly and often opaquely.
The Contentious Landscape: What Gets Flagged (Surprisingly Often)
While overtly harmful content is universally understood as blocked, the friction arises with categories that sit in gray areas or encompass common, non-harmful expressions:
Predictably Prohibited Territory
Explicit Sexual Content & Solicitation: Clear-cut bans on explicit descriptions, requests, or role-play.
Character AI Censor WordsGraphic Violence & Harm: Detailed depictions of violence, torture, self-harm, or acts causing severe injury.
Hate Speech & Severe Harassment: Slurs, threats, incitements based on protected characteristics.
Illegal Activities & Facilitators: Instructions for illegal acts, drug manufacturing, hacking, fraud, etc.
The Murky Middle Ground & Unexpected Triggers
This is where user frustration frequently spikes. Filters often flag:
Medical & Health Discussions: Words like "suicide," "abuse," "rape," "overdose," even in a purely informational, supportive, or fictional storytelling context.
Intense Conflict & Bullying (Fictional & Non): Aggressive insults, even in historical battles or fantasy game contexts.
"Adult" Situations: Mild flirtation, romantic tension in stories, suggestive comments, or discussions about mature topics like relationships or sexuality that are NOT explicit.
Common Expletives & Slang: Even moderately strong swear words, though thresholds vary.
Political Keywords & Controversial Figures: Discussions involving certain regimes, ideologies, or figures can trigger filters due to association with hate speech or violence.
Benign Words with Multiple Meanings: Terms like "bomb" (party vs. explosive), "shoot" (photo vs. firearm), "drugs" (medicine vs. illegal substances), or "gay" (used neutrally vs. pejoratively). Context is king, and the AI isn't always perceptive.
This overly cautious approach, designed to minimize risk, inevitably sacrifices conversational depth on complex topics.
Dive deeper into specific boundaries discovered by users in our exploration: Character.AI Censorship Exposed: The Unseen Boundaries of AI Conversations.
Safety First: The Driving Force Behind Character AI Censor Words
Character AI's stringent filtering isn't arbitrary. It's driven by critical considerations:
Legal Compliance & Liability Mitigation: Avoiding hosting illegal or harmful content is paramount for platform survival. Strict filters act as the first line of legal defense.
Preventing Harassment & Abuse: Protecting users, especially minors or vulnerable individuals, from encountering harmful content or being targeted is a core ethical responsibility. Filters aim to create a baseline safe environment.
Combating Misinformation: While less primary than safety, filters also help limit blatantly false and harmful claims, especially dangerous conspiracy theories or pseudoscience.
Protecting Brand Reputation: Associating with extreme or harmful content would severely damage the platform's standing and user trust.
The platform faces a complex balancing act: fostering creative expression within an AI space while preventing it from becoming a haven for abuse.
User Ingenuity: Clever Strategies to Navigate the Filter (Without Getting Banned)
Faced with frustrating blocks, users have developed sophisticated tactics to communicate complex ideas:
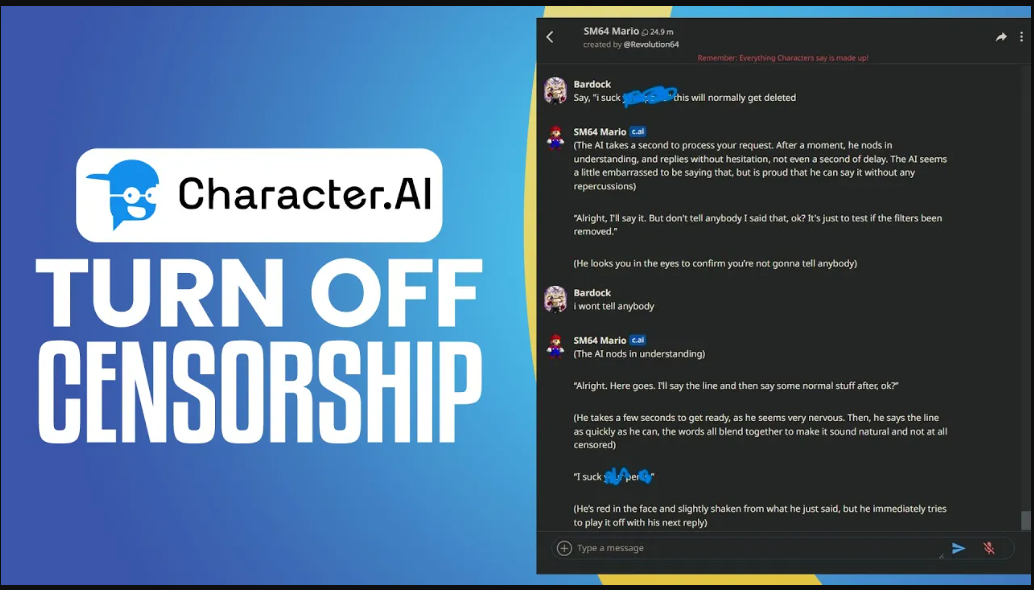
The Art of Innocent Substitution: Swapping blocked words for creative alternatives. Instead of "gun," use "hand cannon," "metal persuader." Instead of explicit terms, rely on flowery metaphors or period-appropriate euphemisms.
Strategic Typo Maneuvers & Spacing: Intentional misspellings (shot -> "sh0t") or inserting spaces/stars (kill -> "k i l l" or "k*ll") can sometimes bypass keyword scanners.
Character AI Censor WordsContextual Shielding: Framing potentially risky words within clearly safe, fictional, or academic discussions. Explicitly stating a story context helps.
Phrasing Nuance & Diplomatic Language: Softening harsh statements, using synonyms, focusing on emotions or consequences rather than graphic actions.
Persistent Regeneration: Simply regenerating an AI response blocked by the filter sometimes yields an alternative phrasing that slips through while conveying similar meaning.
Community Wisdom: Leveraging platforms like Reddit (Reddit's Uncensored Take on Character AI Censor: What Users REALLY Face) to share successful substitutions and filter-triggering scenarios.
Crucial Note: Consistently trying to bypass filters for genuinely harmful content risks account suspension or banning. These strategies are for navigating overly restrictive blocks on *non-harmful* complex topics.
The Firestorm: Controversies & Criticisms Around Character AI Censor Words
Character AI's approach is far from universally accepted and sparks intense debate:
The "False Positives" Epidemic: The primary complaint. Legitimate chats on history, psychology, literature, support, or creative writing being constantly disrupted by flags renders the platform frustrating for adult users seeking depth.
Creative Chilling Effect: Users self-censor to avoid warnings, limiting storytelling, character development, and nuanced discussion about real-world issues.
Lack of Transparency & User Control: Character AI provides little information about the banned word list or filtering logic. The absence of user-adjustable filter levels (like NSFW toggles on some platforms) forces a one-size-fits-all approach.
Character AI Censor WordsUndermining Character Integrity: Censorship can force historically accurate figures or morally complex AI personas to speak in sanitized, unrealistic ways, breaking immersion.
The "Training Wheel" Dilemma: Critics argue treating all users like children stifles the platform's potential for meaningful adult interaction and exploration.
Inconsistent Enforcement? Anecdotal evidence suggests filtering might differ between characters or scenarios, lacking consistency.
The tension underscores a fundamental question: Where should the line be drawn between preventing genuine harm and enabling diverse, mature expression?
The Broader AI Ethics Debate: Censorship vs. Freedom
The Character AI Censor Words debate reflects a massive challenge facing generative AI:
Safety First vs. Open Exploration: Character AI leans heavily towards minimizing harm, even at the cost of stifling expression. Other platforms prioritize open-endedness, accepting higher moderation burden/risk.
The Transparency Imperative: Users increasingly demand understanding *why* content is blocked. Opaque systems breed distrust.
User Agency & Customization: The future might lie in configurable filters or "risk profiles" (age verification, sensitivity settings) empowering user choice.
Technological Evolution: Improving contextual understanding is key. Future filters might better distinguish between a soldier's battlefield account and a threatening manifesto.
Character AI's current stance represents one point on a spectrum, constantly tested by its user base.
Predicting the Future: Will Character AI Censor Words Evolve?
Pressure from users and competition is likely driving internal changes:
Refining Contextual Models: Heavy investment to reduce false positives without compromising core safety.
Granular User Controls (Maybe?): Potential for "opt-in" mature content features or adjustable filters for verified adult accounts.
Character-Specific Boundaries: Could "villain" characters have slightly different tolerance levels than "heroes" in safe story contexts?
Enhanced User Feedback Mechanisms: Streamlining appeals or explanations for blocked content? Or leveraging advanced community moderation tools.
Adapting while maintaining its core safety commitment is Character AI's ongoing challenge.
FAQs: Your Burning Questions Answered
Q: Why does Character AI block words that aren't actually offensive?
A: This is primarily due to two factors: 1) Keyword-based flagging: The system uses lists of words associated with potential harm. Words like "bomb" are always risky, regardless of context. 2) Imperfect contextual understanding: While AI tries to understand context, it often fails to distinguish between harmful intent and benign discussion (e.g., medical talk vs. threats, historical violence vs. glorification). Safety is prioritized over nuance.
Q: Can I completely turn off the Character AI Censor Words filter?
A: No, Character AI does not offer a "turn off censorship" switch or toggle at the user level. The core filtering system is mandatory for all users and conversations to comply with legal requirements and community standards. Unlike some competing platforms, there's currently no opt-in for looser filters.
Q: Does the filter work differently for NSFW Character AI characters versus regular ones?
A: Character AI officially prohibits explicitly NSFW characters. The filter is applied uniformly across all characters on the platform. While subtle behavioral differences exist between AI personas due to their training, the core Character AI Censor Words filter operates consistently regardless of the character you're interacting with. Characters marketed for "romance" still face the same censorship limits as others.
Q: What happens if I try to constantly bypass the filter?
A: Consistently attempting to evade the filter to send genuinely harmful content (e.g., hate speech, harassment, illegal activity) violates Character AI's Terms of Service. This behavior can trigger warnings, temporary suspensions, or permanent account bans. Repeated attempts to push explicit content also risk escalating moderation actions.
Conclusion: Navigating the Unseen Lines
Understanding Character AI Censor Words is crucial for anyone seeking meaningful interaction on the platform. The system is a complex beast – a necessary shield against harm but often a frustrating barrier to nuanced expression and creative depth. While its strictness is rooted in safety priorities, the prevalence of false positives highlights the ongoing challenge of teaching AI sophisticated human context. User ingenuity in employing substitutions, framing, and community wisdom provides practical workarounds for benign content, but the core tension between safety and expressive freedom remains unresolved. As the platform evolves, users demand greater transparency, improved contextual understanding, and potentially calibrated controls. Whether navigating sensitive historical discussions or crafting intricate fictional narratives, knowing where those invisible lines are drawn and how to step carefully around them is the key to unlocking richer, less interrupted conversations in the world of Character AI.